In this in-class assignment, we visualise the comparison of two different variables of our proposed datasets in Assignment 1 via a scatterplot using “ggplot2” package.
library(ggplot2)library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
##reimport the datasetyoutube <-read.csv("/Users/nidadonmez/Downloads/trending_yt_videos_113_countries.csv")
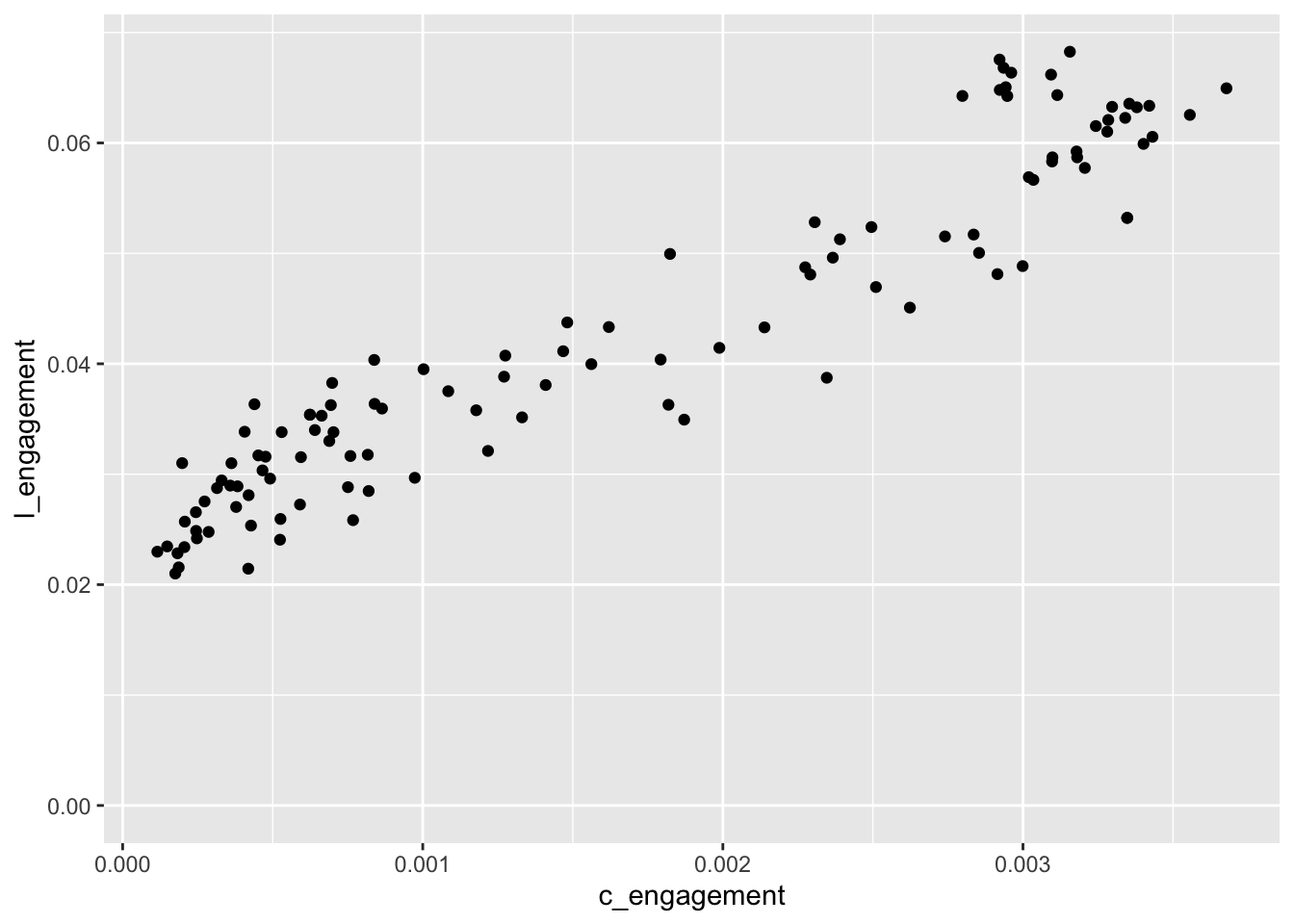
I would like to check for any relationship between the comment engagement and the like engagement in terms of views in a scatterplot:
## summarise the data first to see how each variable looksc_l_by_country <- youtube %>%group_by(country) %>%summarise(c_engagement =sum(comment_count)/sum(view_count), l_engagement =sum(like_count)/sum(view_count))c_l_by_country
# A tibble: 113 × 3
country c_engagement l_engagement
<chr> <dbl> <dbl>
1 AE 0.00227 0.0487
2 AL 0.000116 0.0230
3 AM 0.000247 0.0242
4 AR 0.00343 0.0606
5 AT 0.00303 0.0567
6 AU 0.00262 0.0451
7 AZ 0.000287 0.0248
8 BA 0.000148 0.0235
9 BD 0.000820 0.0285
10 BE 0.000530 0.0338
# ℹ 103 more rows
The comment engagement rate by country can vary in terms of decimels while like engagement is in general point two decimels. In this case, it can be difficult to summarise y values around proper numbers, but we can try:
##a scatterplot as below can be created. ggplot(c_l_by_country, aes(x = c_engagement, y = l_engagement)) +geom_point() +expand_limits(y=0)
##expand_limits equaled to 0 to start each row by 0 to see clearly
Comment rate looked very varied having values less than e-4 and e-3 on the initial rows of data, making us think that it might also include values of until e-1 decimels. However, in the summary of the scatterplot, we can see that it is proper data in between 0 to 0.003. In this case, the scatterplot brought us a clear summary where we can see a positive correlation between the comment engagement and the like engagement.