I’m Gözde Uğur. I’ve been working as Senior Data Analyst at Trendyol for almost 2 years. Since graduating from university, I have worked in various data analyst roles where I mainly used SQL. I want to make sophisticated analyzes and visualizations of data with what I learned in this program. You can check My Linkedin Page for further info.
1.2 Bridging the Gap between SQL and R
The reason I chose this video called Bridging the Gap between SQL and R was that I was curious about ways to use SQL, which I use frequently in daily life, in R. In this video, I learned an R package, tidyquery, with which I can run SQL Queries directly.
1.3 Dataset
1.3.1 Amazon Products Dataset 2023
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
# Using read.csv()myData =read.csv("/Users/gozde.ugur/Downloads/archive (3)/amazon_products.csv") en_cok_satanlar <- myData %>%arrange(desc(boughtInLastMonth)) %>%# satisadedi sütununa göre azalan sırada sıralahead(5) # İlk 5 kaydı getirilk_5_kayit <- head(myData, 5)# Show only selected columnssecilen_sutunlar <- en_cok_satanlar[, c("title","stars", "price" ,"boughtInLastMonth")]print(secilen_sutunlar)
title
1 Bounty Quick Size Paper Towels, White, 8 Family Rolls = 20 Regular Rolls
2 Amazon Brand - Presto! Flex-a-Size Paper Towels, 158 Sheet Huge Roll, 12 Rolls (2 Packs of 6), Equivalent to 38 Regular Rolls, White
3 Stardrops - The Pink Stuff - The Miracle All Purpose Cleaning Paste
4 Amazon Basics 2-Ply Paper Towels, Flex-Sheets, 150 Sheets per Roll, 12 Rolls (2 Packs of 6), White
5 Hismile v34 Colour Corrector, Tooth Stain Removal, Teeth Whitening Booster, Purple Toothpaste, Colour Correcting, Hismile V34, Hismile Colour Corrector, Tooth Colour Corrector
stars price boughtInLastMonth
1 4.8 24.42 100000
2 4.7 28.28 100000
3 4.4 4.99 100000
4 4.2 22.86 100000
5 3.4 20.69 100000
Since I work in the e-commerce industry, Amazon Products Dataset 2023 attracted my attention. Reasons why I find this dataset useful for out course:
1. We may have the opportunity to get more insight about the trends and behaviors in the e-commerce industry, where we are usually on the customer side.
2. This dataset allows us to work with different data types such as boolean, integer, float and character.
3. This dataset contains 1.4M records. Although we work with much larger datasets in real business life, working with this dataset can also be a good opportunity to learn and overcome the difficulties of large datasets.
1.4 R posts relevant to my interests
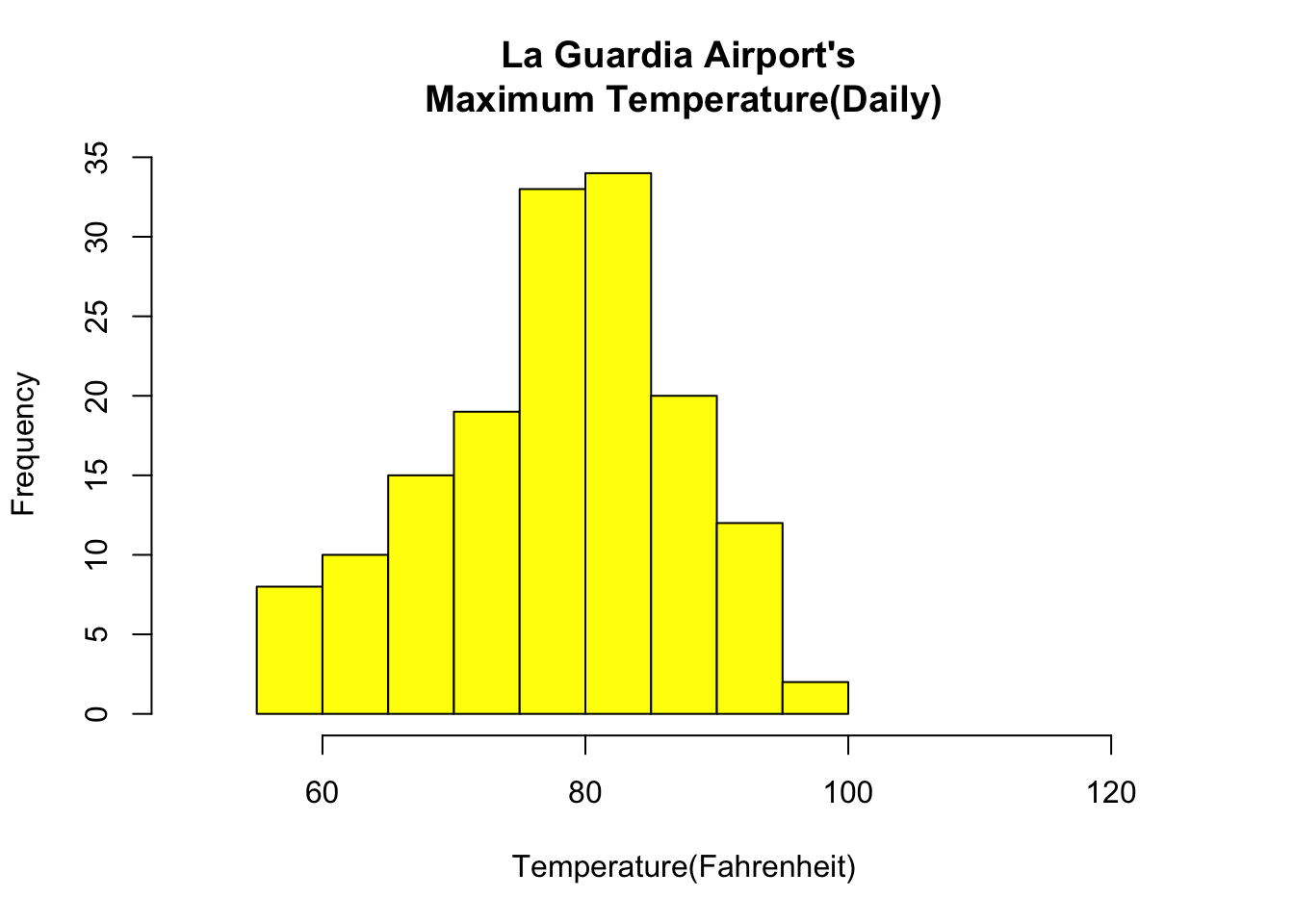
1.5 R Histogram
A histogram is like a bar chart as it uses bars of varying height to represent data distribution. However, in a histogram values are grouped into consecutive intervals called bins. In a Histogram, continuous values are grouped and displayed in these bins whose size can be varied.
Example:
# Histogram for Maximum Daily Temperature data(airquality) hist(airquality$Temp, main ="La Guardia Airport's\ Maximum Temperature(Daily)", xlab ="Temperature(Fahrenheit)", xlim =c(50, 125), col ="yellow", freq =TRUE)
1.6 Hypothesis Testing in R Programming
hypothesis is made by the researchers about the data collected for any experiment or data set. A hypothesis is an assumption made by the researchers that are not mandatory true. In simple words, a hypothesis is a decision taken by the researchers based on the data of the population collected. Hypothesis Testing in R Programming is a process of testing the hypothesis made by the researcher or to validate the hypothesis. To perform hypothesis testing, a random sample of data from the population is taken and testing is performed. Based on the results of the testing, the hypothesis is either selected or rejected. This concept is known as Statistical Inference. In this article, we’ll discuss the four-step process of hypothesis testing, One sample T-Testing, Two-sample T-Testing, Directional Hypothesis, one sample -test, two samples -test and correlation test in R programming.
1.6.0.1 One Sample T-Testing
One sample T-Testing approach collects a huge amount of data and tests it on random samples. To perform T-Test in R, normally distributed data is required. This test is used to test the mean of the sample with the population. For example, the height of persons living in an area is different or identical to other persons living in other areas.
Syntax: t.test(x, mu) Parameters:x: represents numeric vector of data mu: represents true value of the mean
To know about more optional parameters of t.test(), try the below command:
help("t.test")
Example:
# Defining sample vectorx <-rnorm(100)# One Sample T-Testt.test(x, mu =5)
One Sample t-test
data: x
t = -53.822, df = 99, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 5
95 percent confidence interval:
-0.1435268 0.2222364
sample estimates:
mean of x
0.0393548
1.7 Reading a .csv File in R
read.csv(): read.csv() is used for reading “comma separated value” files (“.csv”). In this also the data will be imported as a data frame.
file: the path to the file containing the data to be imported into R.
header: logical value. If TRUE, read.csv() assumes that your file has a header row, so row 1 is the name of each column. If that’s not the case, you can add the argument header = FALSE.
sep: the field separator character
dec: the character used in the file for decimal points.
library(dplyr)# Using read.csv()myData =read.csv("/Users/gozde.ugur/Downloads/movies.csv") # Show only first 5 recordcomedy_filmler <- myData %>%filter(Genre =="Comedy")ilk_5_kayit <-head(comedy_filmler, 5)# Show only selected columnssecilen_sutunlar <- ilk_5_kayit[, c("Film", "Genre", "Year")]print(secilen_sutunlar)
Film Genre Year
1 Youth in Revolt Comedy 2010
2 You Will Meet a Tall Dark Stranger Comedy 2010
3 When in Rome Comedy 2010
4 What Happens in Vegas Comedy 2008
5 Valentine's Day Comedy 2010
 -test, two samples
-test, two samples